Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu* Taesung Park* Phillip Isola Alexei A. Efros
UC Berkeley
In ICCV 2017
Paper | PyTorch code | Torch code

Abstract
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples. Our goal is to learn a mapping G: X → Y, such that the distribution of images from G(X) is indistinguishable from the distribution Y using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping F: Y → X and introduce a cycle consistency loss to push F(G(X)) ≈ X (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.

Paper
arxiv 1703.10593, 2017.
Citation
Jun-Yan Zhu*, Taesung Park*, Phillip Isola, and Alexei A. Efros. "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks", in IEEE International Conference on Computer Vision (ICCV), 2017.
(* indicates equal contributions)
Bibtex
Code: PyTorch | Torch
If you have questions about our PyTorch code, please check out model training/test tips and frequently asked questions.
Course
CycleGAN course assignment code and handout designed by Prof. Roger Grosse for "Intro to Neural Networks and Machine Learning" at University of Toronto. Please contact the instructor if you would like to adopt this assignment in your course.
Other Implementations
Tensorflow (Harry Yang) |
Tensorflow (Archit Rathore) |
Tensorflow (Van Huy) |
Tensorflow (Xiaowei Hu) |
TensorLayer (luoxier)
Tensorflow-simple (Zhenliang He) |
Chainer (Yanghua Jin) |
Minimal PyTorch (yunjey) |
Mxnet (Ldpe2G) |
lasagne/keras (tjwei)
ICCV Spotlight Talk
Expository Articles and Videos
Two minute papersKaroly Zsolnai-Feher made the above as part of his very cool "Two minute papers" series. |
Understanding and Implementing CycleGAN
Nice explanation by Hardik Bansal and Archit Rathore, with Tensorflow code documentation. |
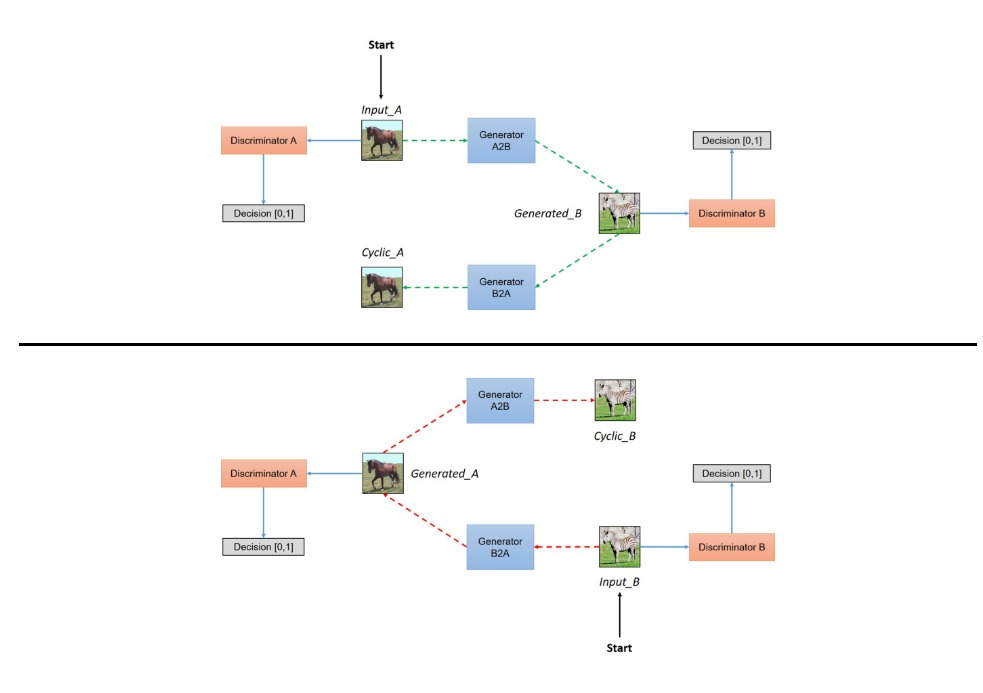
Creative Applications of CycleGAN
Researchers, developers and artists have tried our code on various image manipulation and artistic creatiion tasks. Here we highlight a few of the many compelling examples. Search CycleGAN in Twitter for more applications.
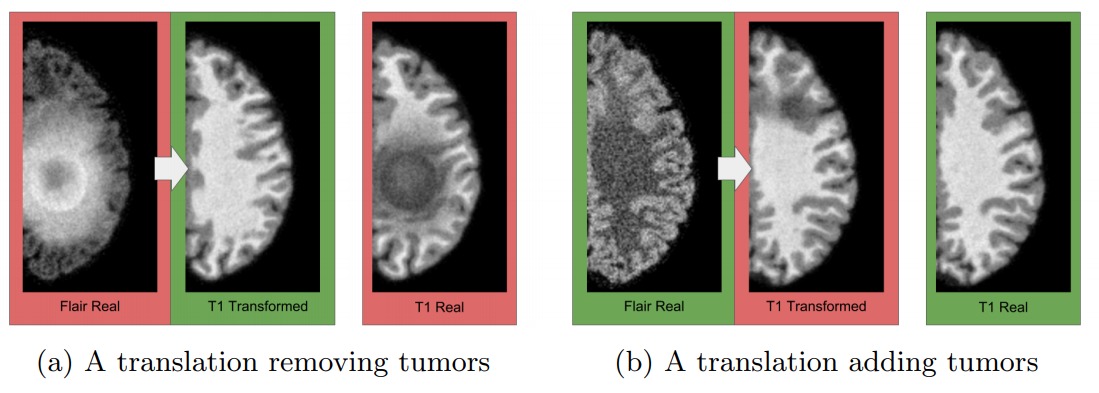
How to interpret CycleGAN results: CycleGAN, as well as any GAN-based method, is fundamentally hallucinating part of the content it creates. Its outputs are predictions of "what might it look like if ..." and the predictions, thought plausible, may largely differ from the ground truth. CycleGAN should only be used with great care and calibration in domains where critical decisions are to be taken based on its output. This is especially true in medical applications, such as translating MRI to CT data. Just as CycleGAN may add fanciful clouds to a sky to make it look like it was painted by Van Gogh, it may add tumors in medical images where none exist, or remove those that do. More information on dangers like this can be found in Cohen et al.
Converting Monet into Thomas Kinkade
What if Claude Monet had lived to see the rise of Americana pastoral kitsch in the style of Thomas Kinkade? And what if he resorted to it to support himself in his old age? Using CycleGAN, our great David Fouhey finally realized the dream of Claude Monet revisiting his cherished work in light of Thomas Kinkade, the self-stylized painter of light. |
Resurrecting Ancient Cities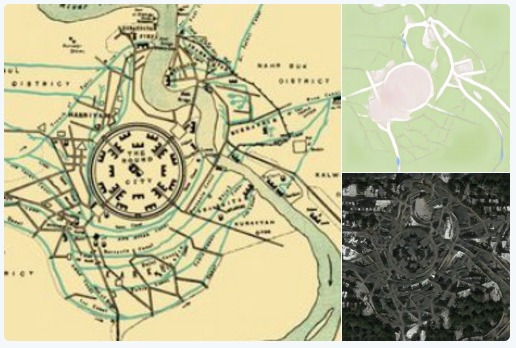
Jack Clark used our code to convert ancient maps of Babylon, Jerusalem and London into modern Google Maps and satellite views. |
Animal Transfiguration
Tatsuya Hatanaka trained our method to translate black bears to pandas. See more examples and download the models at the website. Matt Powell performed transfiguration between different species of birds |
Portrait to Dollface
Mario Klingemann used our code to translate portraits into dollface. See how the characters in Game of Thrones look like in the doll world. |
Face ↔ Ramen
Takuya Kato performed a magical and hilarious Face ↔ Ramen translation with CycleGAN. Check out more results here |
Colorizing legacy photographs
Mario Klingemann trained our method to turn legacy black and white photos into color versions. |
Cats ↔ Dogs
itok_msi produced cats ↔ dogs CycleGAN results with a local+global discriminator and a smaller cycle loss. |
The Electronic CuratorEran Hadas and Eyal Gruss used CycleGAN to convert human faces into vegetable portraits. They built a real-time art demo which allows users to interact with the model with their own faces. |
Turning Fortnite into PUBGChintan Trivedi used CycleGAN to translate between Fornite and PURB, two popular Battle Royale games with hundreds of millions of users. Now you can enjoy the gameplay of one game in the visuals of the other. Check out his blog for more cool demos. |
Popular Press
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Applications in our Paper
Monet Paintings → Photos Mapping Monet paintings to landscape photographs from Flickr: |
 |
Collection Style Transfer Transferring input images into artistic styles of Monet, Van Gogh, Ukiyo-e, and Cezanne. |
 |
Object Transfiguration Object transfiguration between horses and zebras: |
 |
Horse Video to Zebra Video |
|
|
 |
Season Transfer Transferring seasons of Yosemite in the Flickr photos: |
 |
Photo Enhancement iPhone photos → DSLR photos: generating photos with shallower depth of field. |
 |
Experiments and comparisons
- Comparison on Cityscapes: different methods for mapping labels ↔ photos trained on Cityscapes.
- Comparison on Maps: different methods for mapping aerialphotos ↔ maps on Google Maps.
- Facade results: CycleGAN for mapping labels ↔ facades on CMP Facades datasets.
- Ablation studies: different variants of our method for mapping labels ↔ photos trained on Cityscapes.
- Image reconstruction results: the reconstructed images F(G(x)) and G(F(y)) from various experiments.
- Style transfer comparison: we compare our method with neural style transfer [Gatys et al. '15].
- Identity mapping loss: the effect of the identity mapping loss on Monet to Photo.
Failure Cases
- Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Darrell, Alexei A. Efros, Oliver Wang, and Eli Shechtman "Toward Multimodal Image-to-Image Translation", in NeurIPS 2017.
- Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Alexei A. Efros, and Trevor Darrell "CyCADA: Cycle-Consistent Adversarial Domain Adaptation", in ICML 2018.

Our model does not work well when a test image looks unusual compared to training images, as shown in the left figure. See more typical failure cases [here]. On translation tasks that involve color and texture changes, as many of those reported above, the method often succeeds. We have also explored tasks that require geometric changes, with little success. For example, on the task of dog ↔ cat transfiguration, the learned translation degenerates into making minimal changes to the input. Handling more varied and extreme transformations, especially geometric changes, is an important problem for future work. We also observe a lingering gap between the results achievable with paired training data and those achieved by our unpaired method. In some cases, this gap may be very hard -- or even impossible -- to close: for example, our method sometimes permutes the labels for tree and building in the output of the cityscapes photos → labels task. Resolving this ambiguity may require some form of weak semantic supervision. Integrating weak or semi-supervised data may lead to substantially more powerful translators, still at a fraction of the annotation cost of the fully-supervised systems.
Meet the Authors of CycleGAN
Related Work
Future Work
Here are some future work based on CycleGAN (partial list):
Acknowledgment
We thank Aaron Hertzmann, Shiry Ginosar, Deepak Pathak, Bryan Russell, Eli Shechtman, Richard Zhang, and Tinghui Zhou for many helpful comments. This work was supported in part by NSF SMA-1514512, NSF IIS-1633310, a Google Research Award, Intel Corp, and hardware donations from NVIDIA. JYZ is supported by the Facebook Graduate Fellowship, and TP is supported by the Samsung Scholarship. The photographs used in style transfer were taken by AE, mostly in France.

![[here]](images/failures.jpg){kind=link}