
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
| Unsynchronized z [labels → facades] [edges → shoes] [edges → handbags] [night → day] |
| Synchronized z [labels → facades] [edges → shoes] [edges → handbags] [night → day] |
 |
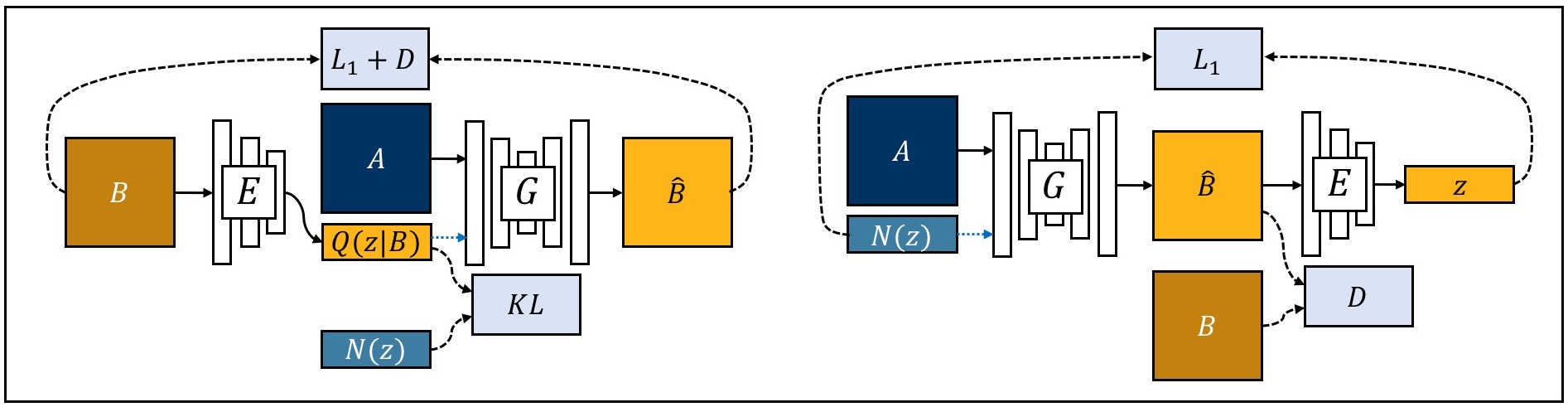 |
 |
J.Y. Zhu, R. Zhang, D. Pathak, T. Darrell, A. A. Efros, O. Wang, E. Shechtman. Toward Multimodal Image-to-Image Translation. In NIPS, 2017. (hosted on arXiv) |
 |
Related WorkJun-Yan Zhu*, Taesung Park*, Phillip Isola, Alexei A. Efros. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In ICCV, 2017. [PDF] [Website] |
AcknowledgementsWe thank Phillip Isola and Tinghui Zhou for helpful discussions. This work wassupported in part by Adobe Inc., DARPA, AFRL, DoD MURI award N000141110688, NSF awards IIS-1633310, IIS-1427425, IIS-1212798, the Berkeley Artificial Intelligence Research (BAIR) Lab,and hardware donations from NVIDIA. JYZ is supported by the Facebook Graduate Fellowship, RZ by the Adobe Research Fellowship, and DP by the NVIDIA Graduate Fellowship. |